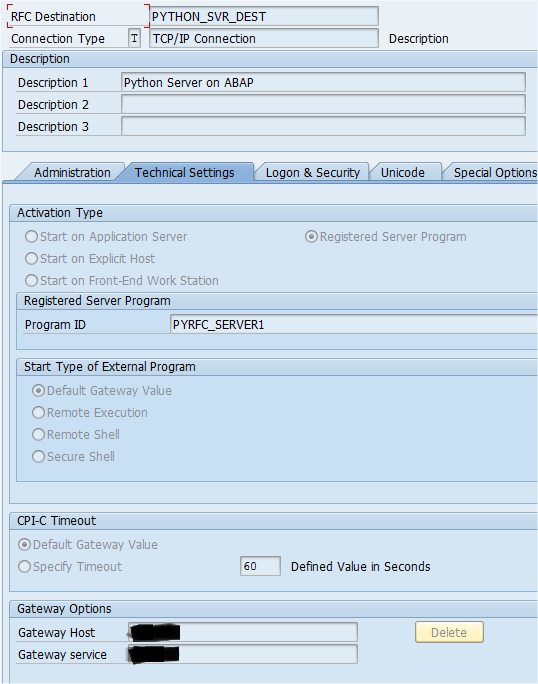
Three days ago, my friends at Packt Publishing send me a free ebook called PhoneGap Beginner's Guide. And while I knew about PhoneGap I had never really use it...so of course, my first thought was...How can I make this work with SAP HANA?
Two days ago, I started to read the book and make the PhoneGap installation...which was a total pain and didn't even work...so I simply put it aside for next year...
Yesterday...my developer spirit could more than me...and since 9 am to 11:30 pm I embarked myself on a crusade to have PhoneGap up and running and of course...to make it work with SAP HANA...here's my story...so you don't have to break your head
- Download and uncompress Eclipse Classic.
- Download and install the Android SDK.
- Download and install the ADT plugin.
- Download and extract Corbova (PhoneGap).
- Download and install Java SDK.
- Download and install Apache Ant.
With all that...I was almost ready to go...as I was missing the Cordova-2.2.0.jar file...for that...I did the following...
- Download and copy into the Cordova\libs folder the commons-codec-1.7.jar.
- I went to Cordova\android\framework\scr\org\apache\cordova and modified the file CordovaWebView.java by commenting out this two lines...
- if(android.os.Build.VERSION.SDK_INT < android.os.Build.VERSION_CODES.HONEYCOMB) settings.setNavDump(true);
- Using CMD, I went to the Cordova\android\framework directory and execute ==> ant jar.
Now...I was really ready to go...so I create a folder called Projects inside Corbova...and again on CMD I did the following...
- Inside Corbova\Projects ==> create C:\Cordova\Projects com.BlagTest BlagTest
That created a Blag_Test folder with all the related files from the Cordova project. Then I simply upload it to Eclipse, and made a couple of test to see if everything was working as expected...it did...so the new odyssey for SAP HANA was going to start...
At first...my initial thought was...this should be easy...I have already do it on PowerBuilder, so basically I need to import the ngdbc.jar into my Eclipse Project and that's it...wrong! Didn't work...and after several tries and fails...I finally see the light...I delete the project from Eclipse...copy the ngdbc.jar inside my libs folder of BlagTest...re-imported on Eclipse...and magically...I got a connection to SAP HANA...
Now...make that connection work was another nightmare...for this blog I needed to undust my almost forgotten knowledge of Java and JavaScript...and also...learn new things like PhoneGap and JQueryMobile...
But...I'm going to try to keep the long story short, so you don't get bored...
- I create a new class called MyClass.java (I was tired...so forget about the silly name)
| MyClass.java |
|---|
package com.BlagTest;
import java.sql.*;
import java.util.ArrayList;
public class MyClass {
public ArrayList<String> getData(String p_carrid){
Connection connection = null;
ArrayList<String> carrid = new ArrayList<String>();
String data = "";
try{
Class.forName("com.sap.db.jdbc.Driver");
try{
connection =
DriverManager.getConnection("jdbc:sap://XX.XX.XXX.XXX:30115",
"SYSTEM","manager");
}
catch (SQLException e){
}
}
catch (ClassNotFoundException e){
}
if(connection != null){
try{
String sqlstring = "select CONNID, FLDATE, PRICE from
SFLIGHT.SFLIGHT where carrid = '" + p_carrid + "'";
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery(sqlstring);
while(rs.next()){
data = rs.getString("CONNID") + "/" +
rs.getString("FLDATE") + "/" +
rs.getString("PRICE");
carrid.add(data);
}
}
catch(SQLException e){
}
}
return carrid;
}
}
|
In this file, what I'm doing is establishing an JDBC connection to my SAP HANA Server hosted on TK ucloud biz. The I'm selecting the CONNID, FLDATE and PRICE from the SFLIGHT table where the CARRID is going to be a parameters send from the application. As I didn't want to pass a multidimensional array, or an array of arrays, or anything like that...I simply concatenate the values using a "/" to split them later.
- I modified the already existing BlagTest.java file
| BlagTest.java |
|---|
package com.BlagTest;
import android.app.Activity;
import android.os.Bundle;
import org.apache.cordova.*;
public class BlagTest extends DroidGap
{
private MyClass mc;
@Override
public void onCreate(Bundle savedInstanceState)
{
super.onCreate(savedInstanceState);
super.init();
mc = new MyClass();
super.appView.getSettings().setJavaScriptEnabled(true);
super.appView.addJavascriptInterface(mc, "MyCls");
super.loadUrl("file:///android_asset/www/index.html");
}
}
|
Here, basically we saying that we want to be able to send data from Java to JavaScript by using the setJavaScriptEnabled(true) and then adding the addJavaScriptInterface(mc, "MyCls") we're telling how our class is going to be called...when we call them from JavaScript.
- Finally...I delete everything from the already generated index.html file and put this code...
| index.html |
|---|
<html>
<head>
<title>SAP HANA from PhoneGap</title>
<meta name="viewport" content="width=device-width, initialscale=1.0"></meta>
<link rel="stylesheet" href="http://code.jquery.com/mobile/1.1.0/jquery.mobile-1.1.0.min.css"/>
<script src="http://code.jquery.com/jquery-1.7.1.min.js"></script>
<script src="http://code.jquery.com/mobile/1.1.0/jquery.mobile-1.1.0.min.js"></script>
<script>
function getData(){
var carridField = document.getElementById('carrid');
var getCarrid = carridField.value;
var myArrayList = window.MyCls.getData(getCarrid);
carridField.value = "";
$("#content").append("<ul id='list' data-role='listview' data-inset='true'</ul>");
$("#content").trigger("create");
for(var i = 0; i < myArrayList.size(); i++){
var array = "" + myArrayList.get(i);
array = array.split('/');
var _connid = array[0], _fldate = array[1], _price = array[2];
var list = "<li><p>CONNID: " + _connid + "</p><p>FLDATE: " +
_fldate + "</p><p>PRICE: " + _price + "</p></li>";
$("#list").append(list);
}
$("#list").listview("refresh");
}
</script>
</head>
<body>
<div data-role="page">
<div data-role="content" id="content">
<div align="center"><h1>SAP HANA from PhoneGap</h1></div>
Carrid: <input type="text" id="carrid" size="2"/>
<button id="submitCarrid" onClick="getData()">Submit</button>
</div>
</div>
</body>
</html>
|
What I'm doing here...is as following...
- I have an input text and a button. In the input text, we're going pass an CARRID value and when pressing the button, we're going to call a JavaScript function.
- The JavaScript function will collect the value from the input text, will call our Java function using window.MyCls.getData() and pass the CARRID parameter. This should return an ArrayList...but instead...it return an Object...so we need to handle it later...
- Using JQueryMobile we're going to create a ListView which is like an HTML Table on steroids...and the thing I love about JQueryMobile is that we only need to include one "link rel" and two "script src" lines to make it work...as it grabs it from an on-line location.
- We're going to do a FOR beginning from 0 till the size of our Object, and then will extract it's content using .get() will turning it into an String using "".
- We simply split the newly created String and assign it to variables.
- We add the lines to our ListView and update it when we finish.
After that, we can simply go to Project --> Clean to rebuild our project and then right click on our Project Folder and choose Run As --> Android Application.




It took so long time...but the rewards can't be greater...hope you like this -:)
Greetings,
Blag.